
在Gartner最新發布的《2024年人工智能技術成熟度曲線》中,邊緣人工智能(Edge AI)正處于技術關注度的頂峰——"期望膨脹頂點"。這個關鍵節點既昭示著整個行業的熱度,也暗藏著即將面臨的諸多挑戰。
邊緣 AI 市場正經歷高速增長。機構預測顯示,到 2032 年,其市場規模或將達到 396.1 億美元(復合年增長率 20.8%)。這種增長源于芯片算力提升等技術突破,也得益于各行業應用場景的持續拓展。
根據曲線揭示的技術演進規律,Edge AI當前正處于從概念驗證向實際應用轉折的關鍵期。Gartner數據顯示,2024年全球Edge AI初創企業融資突破34億美元,較上年增長62%,但同期概念驗證(POC)項目失敗率高達45%。這種冰火交織的現狀,折射出技術理想與工程現實間的巨大鴻溝。
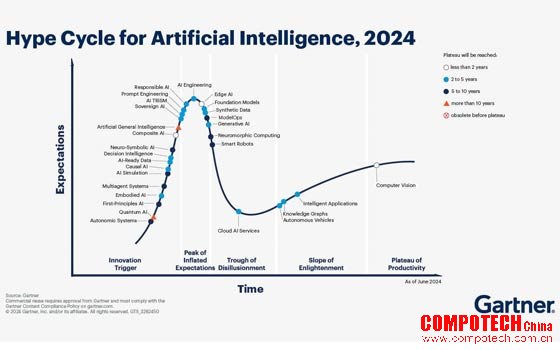
圖:2024年人工智能技術成熟度曲線 圖片來源:Gartner
一方面,第三代邊緣芯片(如輝達Jetson Orin Nano)雖已實現12TOPS/W的能效突破,但仍無法滿足全天候智慧設備的續航需求,統計顯示輕量化模型規模平均準確率較云端模型下降18.7%(MLPerf 2024基準檢驗);另一方面混合架構崛起:AWS Wavelength等公司的邊緣云服務已覆蓋全球86%區域,形成"端-邊-云"三級算力網絡,對于后來的市場挑戰者來說難度更高了。但同時,這些因素也會激勵后來者們去突破目前的困境。
物聯網的邊緣 AI 可顯著降低延遲、提升系統可靠性。Gartner 預測,到 2026 年,全球 50% 的邊緣部署將集成AI,在工業、農業、醫療、環境監測、智慧城市管理等應用領域,Edge AI正在加速向各行業滲透。
歐盟《邊緣計算數據法案》要求醫療/金融數據必須本地化處理,英國已將邊緣節點納入碳積分體系,IEEE白皮書指出,邊緣計算較云端降低32%碳排放;FDA在最近幾個月批準多項款Edge AI設備中,手術機器人視覺系統已實現0.1mm級實時組織識別,這些政策的積極因素都會為Edge AI提供動力。
Edge AI 正在與 5G/6G 網絡、神經形態計算、分布式 AI 及云邊混合方案深度集成,進一步提升處理靈活性與效能。
根據市場研究機構 Techno Systems Research 的預測,到 2029 年,LTE Cat 1bis 將占所有非手機蜂巢式裝置的 43.6%,預計在未來四到五年成為邊緣物聯網(IoT)最廣泛使用的蜂巢式技術。u-blox LEXI-R10 Global 是超精巧 16 x16mm LTE Cat 1bis 解決方案,適用于全球各地尺寸受限的物聯網應用,例如人員或寵物追蹤器和穿戴裝置。LEXI-R10 Global 也是全球最小的單模 LTE Cat 1bis 模塊,具有室內定位和美國 MNO 認證核心。

圖:u-blox LEXI-R10 Global 是超精巧 16 x16mm LTE Cat 1bis 解決方案 圖片來源: u-blox
同時,生成式 AI 向邊緣端的遷移加速,有望緩解云端壓力,釋放本地化部署潛力,如邊緣端數智人、機械臂控制等創新應用不斷涌現。
應用場景持續多元拓展其應用從機器視覺等單一領域,向大語言模型、智能機器人等多元場景延伸。例如,邊緣端集成大語言模型(如 Llama 系列)實現本地推理,滿足工業輕量化部署、數據不出廠等需求,為行業應用開辟新維度。
目前,Edge AI 正處于 “期望膨脹頂峰”(Peak of Inflated Expectations)向 “泡沫化谷底”(Trough of Disillusionment)的過渡階段。這預示著短期需克服碎片化場景適配等挑戰,但長期來看,其終將邁入 “光明坡”(Slope of Enlightenment),成為全球數字化轉型浪潮中的關鍵技術。
低功耗到零能耗:μW 級待機成為行業新基準
在能源效率的競賽中,半導體廠商正通過制程創新和動態管理技術突破物理極限。意法半導體(ST)與三星聯合開發的 18nm FD-SOI 制程,通過全耗盡型絕緣體上硅技術,將物聯網MCU的待機功耗降至 1.6μA。這種制程不僅支持 3V 仿真功能,還能在 - 40℃至 105℃的寬溫環境下保持穩定性,已被應用于 Stellar 系列車規級 MCU。德州儀器(TI)的 MSPM0C1104 采用晶圓級芯片封裝(WCSP),在 1.38mm² 的極小面積內實現 0.16 美元的低成本,并通過動態電壓調節(DVFS)將活動功耗控制在 1.38mA/MHz。

圖: TI的 MSPM0C1104 采用晶圓級芯片封裝(WCSP) 圖片來源: 德州儀器(TI)
預計2025 年主流物聯網 MCU 待機功耗普遍進入 μW 級,其中 ST 的 STM32U3 系列通過近閾值設計將動態功耗降至 10μA/MHz,較上一代提升兩倍。這種低功耗特性直接推動了物聯網設備的部署密度 —— 以獨立煙感報警器為例,采用 NXP 低功耗 MCU 的設備可通過 9V 電池運行長達 5 年,待機功耗僅 0.3μA。
超低功耗零能耗物聯網計算正在越來越多被部署,例如NXP的無源藍牙標簽通過反向散射技術實現1公里數據傳輸,太陽能農業傳感器在沙漠修復項目中成本降至50美元/節點,壽命長達10年。ADI的MAX3865X系列甚至能從-40°C環境中收集熱能,推動無電池設備普及。
AI 加速標準化:更多新品集成專用硬件引擎
AI 推理能力正在成為邊緣設備的標配。瑞薩電子的 RZ/V2N MPU 集成 DRP-AI 加速器,提供 15 TOPS 的 INT8 算力,支持視覺 AI 任務的實時處理。ADI 的 CNN 引擎則通過硬件級優化,在 0.5mW 功耗下實現 1TOPS 的能效比,適用于可穿戴設備的健康監測。市場研究顯示,2025 年 70% 以上的新發布 MCU/MPU 將集成 NPU/TPU,其中瑞薩、NXP、ST 等廠商的產品已支持 INT8/FP16 量化模型。
比如 ST 的 STM32N6 系列,其 NPU 可執行圖像分割和分類任務,而 TI 的 C2000 系列則通過 NPU 實現工業控制中的實時預測性維護。這些加速器的引入使邊緣設備的 AI 推理延遲從毫秒級降至微秒級,例如瑞薩 DRP 技術在圖像處理中比 CPU 快 14 倍,功耗僅為采用CPU方案的 1/20。
無線協議融合:單芯片支持多模切換
隨著 Matter 協議的普及,邊緣物聯網設備互聯互通需求催生了多協議集成芯片。市場數據顯示,2025 年支持多協議的無線芯片出貨量將增長 35%,其中 Wi-Fi 6 與藍牙 5.4 的組合占比超 60%。這種集成化設計顯著降低了開發復雜度 —— 例如,使用 EFR32MG24 的開發者可通過單一芯片實現從設備端到云端的全鏈路通信,無需額外協議轉換模塊。
芯科科技(Silicon Labs)的 EFR32MG24 SoC 支持 Wi-Fi 6、藍牙 5.4、Thread 和 Matter,內置 1.5MB 閃存和 256KB RAM,服務于智慧家居和工業自動化設計。該芯片的無線子系統在 1Mbps GFSK 模式下接收電流僅 4.4mA,發射功率可達 19.5dBm,同時支持硬件級安全防護。
安全與可信計算:硬件級防護成中高端標配
面對日益增長的網絡攻擊威脅,PSA Certified Level 3 和 Arm TrustZone 成為中高端 MCU 的核心賣點。博通整合的 BK7236 芯片通過 PSA Level 2 認證,搭載 Arm TrustZone 技術,支持金融級加密和安全啟動。
業內認為,2025 年將有超過 80% 的中高端 MCU 將集成后量子加密算法,如格基密碼(Lattice)和哈希簽名(SHA-3)。這些技術確保設備在未來 10 年內抵御量子計算攻擊。
例如 NXP 的 i.MX 9 系列通過 EdgeLock 安全區域實現密鑰管理和運行時認證。英飛凌的 AURIX 系列汽車 MCU 則采用雙鎖步 CPU 架構和硬件加密引擎,滿足 ASIL D 功能安全等級。瑞薩RA8系列MCU的PUF 3.0技術可在5μs內生成動態密鑰,特斯拉2024款車型借此防御OTA篡改;NXP的EdgeLock SE050F支持后量子加密,2025年將覆蓋70%工業設備。東芝的光致分解內存能在1秒內焚毀數據,滿足GDPR“被遺忘權”要求。
異構計算:混合架構平衡算力與能效
為應對復雜邊緣計算需求,廠商推出 CPU+GPU+NPU+FPGA 的混合架構,以滿足邊緣段日趨多樣化的計算需求。以NXP 的 i.MX 8MULP為例,其采用 28nm FD-SOI 制程,整合 Cortex-A53、Cortex-M7、GPU 和 NPU,支援 4K 視頻解碼和 AI 推理,同時通過 Energy Flex 架構實現 20 種功耗模式,待機功耗低至 30μW。此外,有廠商則將 RISC-V 內核與 FPGA 結合,適用于工業自動化中的定制化算法加速。
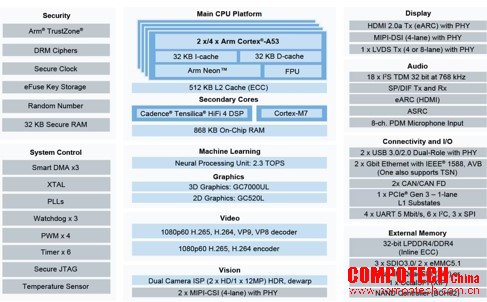
圖: i.MX 8M Plus架構圖 圖片來源:NXP
這種異構設計顯著提升了能效比:例如,i.MX 8MULP在處理視覺任務時,NPU 的能效比是 CPU 的 10 倍,而 FPGA 部分可靈活配置以適應不同算法需求。行業預測,2025 年異構計算架構的市場份額將達 45%,成為邊緣 AI 的主流選擇。
加強開發工具生態:降低 AI 落地門坎
廠商通過預集成 AI 框架和開放硬件加速開發。Meta與ST合作開發的Llama3微型版,可在MCU上實現自然語言交互。Arm與Meta合作的ExecuTorch框架,讓Llama3.2量化模型在端側運行速度達每秒400詞元,虛擬助手響應延遲低于50ms。邊緣設備開始具備“類人決策”能力。
此外,ST 的 SensorTile 開發工具包提供預訓練的 AI 模型和傳感器融合算法,支持 TensorFlow Lite Micro,開發者可在 24 小時內完成從原型到量產的全流程。瑞薩的 e²studio 集成 DRP-AI 工具鏈,允許用戶通過圖形化接口配置硬件加速器,生成優化的 C 代碼。
生態建設方面,NXP 的 EdgeVerse 平臺提供從芯片到云的端到端解決方案,包括預集成的 AI 模型庫和安全認證工具。這些舉措使 AI 開發門坎降低 70%,例如使用 ST SensorTile 的開發者無需具備深度學習專業知識即可部署手勢識別功能。
存算一體:突破馮?諾依曼瓶頸
存算一體(CIM)技術在邊緣端側 AI 芯片中率先落地。傳統AI芯片的“內存墻”問題正被顛覆。美國初創公司Mythic的M1076芯片通過模擬存內計算,以3W功耗實現25TOPS算力,效能比GPU提升數十倍;中國清華大學研發的存算一體芯片在BERT模型推理中,能效比GPU高75倍;蘋芯科技(PIMCHIP)的 PIMCHIP-S300 采用 28nm 制程,通過 SRAM 內計算技術實現 27TOPS/W 的能效比,在特定任務中節省 90% 能耗。該芯片支持多模態感知,可同時處理音訊、視頻和傳感器數據,適用于智能安防和具身智慧。
如技術瓶頸突破順利的話,預計到2027年,這類芯片將占據邊緣AI市場35%的份額。行業預測,2025 年存算一體芯片市場規模將達 125 億元,其中端側應用占比超 60%。
3D 封裝:單芯片實現系統級集成
3D 封裝技術推動 MCU 向 “系統級芯片” 演進。
ST 的 STM32WB 系列則通過 3D 堆棧將 MCU、藍牙模塊和傳感器接口集成在同一封裝內,尺寸縮小 40%,同時支持 - 40℃至 105℃的寬溫運行。市場數據顯示,2025 年 3D 封裝的 MCU 出貨量將增長 50%,成為高端物聯網設備的首選方案。
NXP 的i.MX 8MULP 采用 Chiplet 架構,通過 25μm 超薄硅中介層將 CPU、GPU 和 NPU 呈蜂窩狀排列,熱阻系數降至 0.15℃/W,較傳統設計提升 5 倍。這種設計使芯片在 85℃環境下仍能保持穩定,適用于工業控制和車載系統。
RISC-V挑戰 Arm 霸主地位
RISC-V 架構憑借開源和可定制特性加速滲透。政策推動方面,中國擬出臺《開源 RISC-V 芯片發展指導意見》,目標 2025 年國產 RISC-V 芯片出貨量達 12 億顆,占全球 35%。行業預測,2025 年 RISC-V 在邊緣物聯網的市場份額將突破 25%,尤其在工業控制和消費電子領域形成與 Arm 的競爭格局。
小結
邊緣物聯網的技術演進已呈現出低功耗設計、AI 加速、多協議融合等趨勢,正在重塑硬件架構,而存算一體、3D 封裝和 RISC-V 則預示著計算范式的變革。
附錄:
物聯網邊緣運算的算力
物聯網邊緣運算的算力從微控制器(MCU)到低功耗嵌入式處理器級別,大致數量級如下:
1.微控制器(MCU)
• 算力范圍:MCU主頻通常在幾個MHz到幾百MHz之間,浮點運算性能在幾MFLOPS到幾十MFLOPS之間。
• 應用場景:適用于簡單的傳感器數據采集、基礎的信號處理和簡單的控制任務。例如,一些低功耗的環境監測設備、智能家居傳感器等。
• 特點:算力芯片功耗極低,通常在幾毫瓦到幾十毫瓦,適合電池供電的設備。
2.低功耗嵌入式處理器級別
• 算力范圍:主頻一般在幾百 MHz 到 1 GHz,浮點運算性能在幾十MFLOPS到幾百MFLOPS。
• 應用場景:適用于更復雜的邊緣計算任務,如圖像處理、簡單的機器學習推理等。例如,一些智慧攝像頭、工業物聯網網關等。
• 特點:算力芯片功耗相對較高,但也僅僅是幾百毫瓦到幾瓦范圍,適合對計算能力有一定要求的場景,仍屬于低功耗計算場景。
3.高性能邊緣計算設備
• 算力范圍:在一些高性能的邊緣計算設備上,普遍使用了GPU或FPGA加速卡,特定場景算力可以達到幾個 GFLOPS 到幾十GFLOPS。
• 應用場景:適用于需要實時處理的復雜計算的任務,如深度學習推理、實時視頻分析等。例如,智能交通系統中的車牌識別、行人檢測等。
• 特點:計算芯片功耗較高,通常在幾瓦到幾十瓦,適合對實時性和計算精度要求較高的場景。
物聯網邊緣運算的算力范圍較廣,從幾 MFLOPS到幾十 GFLOPS不等,算力差距甚至可達5個數量級,具體使用取決于應用場景和設備類型。但即便是高性能邊緣計算設備,仍然追求低功耗和高效能這一目標,這是物聯網邊緣計算設備的重要特點。




