
當(dāng)前位置: CompoTech China > 關(guān)鍵技術(shù)和應(yīng)用 >
摘要
本文是系列文章的第二部分,重點介紹卷積神經(jīng)網(wǎng)絡(luò)(CNN)的特性和應(yīng)用。CNN主要用于模式識別和對象分類。在第一部分文章《卷積神經(jīng)網(wǎng)絡(luò)簡介:什么是機器學(xué)習(xí)?——第一部分》中,我們比較了在微控制器中運行經(jīng)典線性規(guī)劃程序與運行CNN的區(qū)別,并展示了CNN的優(yōu)勢。我們還探討了CIFAR網(wǎng)絡(luò),該網(wǎng)絡(luò)可以對圖像中的貓、房子或自行車等對象進行分類,還可以執(zhí)行簡單的語音識別。本文重點解釋如何訓(xùn)練這些神經(jīng)網(wǎng)絡(luò)以解決實際問題。
神經(jīng)網(wǎng)絡(luò)的訓(xùn)練過程
本系列文章的第一部分討論的CIFAR網(wǎng)絡(luò)由不同層的神經(jīng)元組成。如圖1所示,32 × 32像素的圖像數(shù)據(jù)被呈現(xiàn)給網(wǎng)絡(luò)并通過網(wǎng)絡(luò)層傳遞。CNN處理過程的第一步就是提取待區(qū)分對象的特性和結(jié)構(gòu),這需要借助濾波器矩陣實現(xiàn)。設(shè)計人員對CIFAR網(wǎng)絡(luò)進行建模后,由于最初無法確定這些濾波器矩陣,因此這個階段的網(wǎng)絡(luò)無法檢測模式和對象。
為此,首先需要確定濾波器矩陣的所有參數(shù),以最大限度地提高檢測對象的精度或最大限度地減少損失函數(shù)。這個過程就稱為神經(jīng)網(wǎng)絡(luò)訓(xùn)練。本系列文章的第一部分所描述的常見應(yīng)用在開發(fā)和測試期間只需對網(wǎng)絡(luò)進行一次訓(xùn)練就可以使用,無需再調(diào)整參數(shù)。如果系統(tǒng)對熟悉的對象進行分類,則無需額外訓(xùn)練;當(dāng)系統(tǒng)需要對全新的對象進行分類時,才需要額外進行訓(xùn)練。
進行網(wǎng)絡(luò)訓(xùn)練需要使用訓(xùn)練數(shù)據(jù)集,并使用類似的一組測試數(shù)據(jù)集來測試網(wǎng)絡(luò)的精度。例如CIFAR-10網(wǎng)絡(luò)數(shù)據(jù)集為十個對象類的圖像集合:飛機、汽車、鳥、貓、鹿、狗、青蛙、馬、輪船和卡車。我們必須在訓(xùn)練CNN之前對這些圖像進行命名,這也是人工智能應(yīng)用開發(fā)過程中最為復(fù)雜的部分。本文討論的訓(xùn)練過程采用反向傳播的原理,即向網(wǎng)絡(luò)連續(xù)展示大量圖像,并且每次都同時傳送一個目標(biāo)值。本例的目標(biāo)值為圖像中相關(guān)的對象類。在每次顯示圖像時,濾波器矩陣都會被優(yōu)化,這樣對象類的目標(biāo)值就會和實際值相匹配。完成此過程的網(wǎng)絡(luò)就能夠檢測出訓(xùn)練期間從未看到過的圖像中的對象。
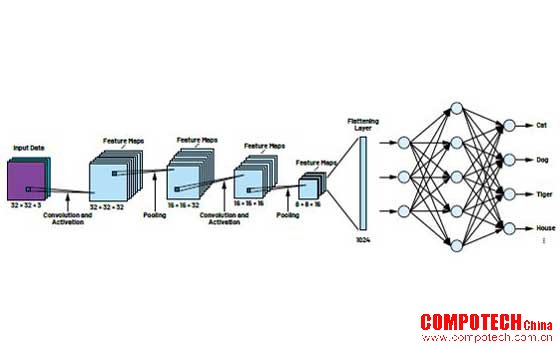
圖1.CIFAR CNN架構(gòu)。
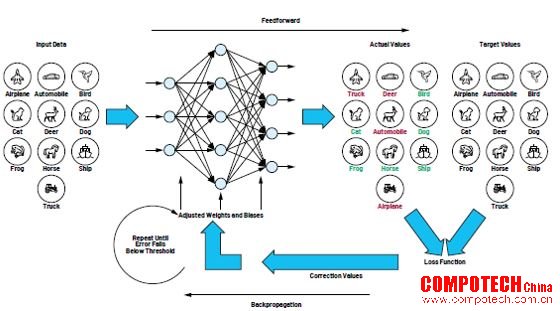
圖2.由前向傳播和反向傳播組成的訓(xùn)練循環(huán)。
過擬合和欠擬合
在神經(jīng)網(wǎng)絡(luò)的建模過程中經(jīng)常會出現(xiàn)的問題是:神經(jīng)網(wǎng)絡(luò)應(yīng)該有多少層,或者是神經(jīng)網(wǎng)絡(luò)的濾波器矩陣應(yīng)該有多大。回答這個問題并非易事,因此討論網(wǎng)絡(luò)的過擬合和欠擬合至關(guān)重要。過擬合由模型過于復(fù)雜以及參數(shù)過多而導(dǎo)致。我們可以通過比較訓(xùn)練數(shù)據(jù)集和測試數(shù)據(jù)集的損失來確定預(yù)測模型與訓(xùn)練數(shù)據(jù)集的擬合程度。如果訓(xùn)練期間損失較低并且在向網(wǎng)絡(luò)呈現(xiàn)從未顯示過的測試數(shù)據(jù)時損失過度增加,這就強烈表明網(wǎng)絡(luò)已經(jīng)記住了訓(xùn)練數(shù)據(jù)而不是在實施模式識別。此類情況主要發(fā)生在網(wǎng)絡(luò)的參數(shù)存儲空間過大或者網(wǎng)絡(luò)的卷積層過多的時候。這種情況下應(yīng)當(dāng)縮小網(wǎng)絡(luò)規(guī)模。
損失函數(shù)和訓(xùn)練算法
學(xué)習(xí)分兩個步驟進行。第一步,向網(wǎng)絡(luò)展示圖像,然后由神經(jīng)元網(wǎng)絡(luò)處理這些圖像生成一個輸出矢量。輸出矢量的最大值表示檢測到的對象類,例如示例中的“狗”,該值不一定是正確的。這一步稱為前向傳播。
目標(biāo)值與輸出時產(chǎn)生的實際值之間的差值稱為損失,相關(guān)函數(shù)則稱為損失函數(shù)。網(wǎng)絡(luò)的所有要素和參數(shù)均包含在損失函數(shù)中。神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)過程旨在以最小化損失函數(shù)的方式定義這些參數(shù)。這種最小化可通過反向傳播的過程實現(xiàn)。在反向傳播的過程中,輸出產(chǎn)生的偏置(損失 = 目標(biāo)值-實際值)通過網(wǎng)絡(luò)的各層反饋,直至達(dá)到網(wǎng)絡(luò)的起始層。
因此,前向傳播和反向傳播在訓(xùn)練過程中產(chǎn)生了一個可以逐步確定濾波器矩陣參數(shù)的循環(huán)。這種循環(huán)過程會不斷重復(fù),直至損失值降至一定程度以下。
優(yōu)化算法、梯度和梯度下降法
為說明訓(xùn)練過程,圖3顯示了一個包含x和y兩個參數(shù)的損失函數(shù)的示例,這里z軸對應(yīng)于損失。如果我們仔細(xì)查看該損失函數(shù)的三維函數(shù)圖,我們就會發(fā)現(xiàn)這個函數(shù)有一個全局最小值和一個局部最小值。
目前,有大量數(shù)值優(yōu)化算法可用于確定權(quán)重和偏置。其中,梯度下降法最為簡單。梯度下降法的理念是使用梯度算子在逐步訓(xùn)練的過程中找到一條通向全局最小值的路徑,該路徑的起點從損失函數(shù)中隨機選擇。梯度算子是一個數(shù)學(xué)運算符,它會在損失函數(shù)的每個點生成一個梯度矢量。該矢量的方向指向函數(shù)值變化最大的方向,幅度對應(yīng)于函數(shù)值的變化程度。在圖3的函數(shù)中,右下角(紅色箭頭處)由于表面平坦,因此梯度矢量的幅度較小。而接近峰值時的情況則完全不同。此處矢量(綠色箭頭)的方向急劇向下,并且由于此處高低差明顯,梯度矢量的幅度也較大。
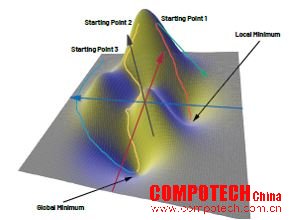
圖3.使用梯度下降法確定到最小值的不同路徑。
因此我們可以利用梯度下降法從任意選定的起點開始以迭代的方式尋找下降至山谷的最陡峭路徑。這意味著優(yōu)化算法會在起點計算梯度,并沿最陡峭的下降方向前進一小步。之后算法會重新計算該點的梯度,繼續(xù)尋找創(chuàng)建一條從起點到山谷的路徑。這種方法的問題在于起點并非是提前定義的,而是隨機選擇的。在我們的三維地圖中,某些細(xì)心的讀者會將起點置于函數(shù)圖左側(cè)的某個位置,以確保路徑的終點為全局最小值(如藍(lán)色路徑所示)。其他兩個路徑(黃色和橙色)要么非常長,要么終點位于局部最小值。但是,算法必須對成千上萬個參數(shù)進行優(yōu)化,顯然起點的選擇不可能每次都碰巧正確。在具體實踐中,這種方法用處不大。因為所選擇的起點可能會導(dǎo)致路徑(即訓(xùn)練時間)較長,或者目標(biāo)點并不位于全局最小值,導(dǎo)致網(wǎng)絡(luò)的精度下降。
因此,為避免上述問題,過去幾年已開發(fā)出大量可作為替代的優(yōu)化算法。一些替代的方法包括隨機梯度下降法、動量法、AdaGrad方法、RMSProp方法、Adam方法等。鑒于每種算法都有其特定的優(yōu)缺點,實踐中具體使用的算法將由網(wǎng)絡(luò)開發(fā)人員決定。
訓(xùn)練數(shù)據(jù)
在訓(xùn)練過程中,我們會向網(wǎng)絡(luò)提供標(biāo)有正確對象類的圖像,如汽車、輪船等。本例使用了已有的CIFAR-10數(shù)據(jù)集。當(dāng)然,在具體實踐中,人工智能可能會用于識別貓、狗和汽車之外的領(lǐng)域。這可能需要開發(fā)新應(yīng)用,例如檢測制造過程中螺釘?shù)馁|(zhì)量必須使用能夠區(qū)分好壞螺釘?shù)挠?xùn)練數(shù)據(jù)對網(wǎng)絡(luò)進行訓(xùn)練。創(chuàng)建此類數(shù)據(jù)集極其耗時費力,往往是開發(fā)人工智能應(yīng)用過程中成本最高的一步。編譯完成的數(shù)據(jù)集分為訓(xùn)練數(shù)據(jù)集和測試數(shù)據(jù)集。訓(xùn)練數(shù)據(jù)集用于訓(xùn)練,而測試數(shù)據(jù)則用于在開發(fā)過程的最后檢查訓(xùn)練好的網(wǎng)絡(luò)的功能。
結(jié)論
本系列文章的第一部分《人工智能簡介:什么是機器學(xué)習(xí)?——第一部分》介紹了神經(jīng)網(wǎng)絡(luò)并對其設(shè)計和功能進行了詳細(xì)探討。本文則定義了函數(shù)所需的所有權(quán)重和偏置,因此現(xiàn)在可以假定網(wǎng)絡(luò)能夠正常運行。在后續(xù)第三部分的文章中,我們將通過硬件運行神經(jīng)網(wǎng)絡(luò)以測試其識別貓的能力。這里我們將使用ADI公司開發(fā)的帶硬件CNN加速器的MAX78000人工智能微控制器來進行演示。
關(guān)于ADI公司
Analog Devices, Inc. (NASDAQ: ADI)是全球領(lǐng)先的半導(dǎo)體公司,致力于在現(xiàn)實世界與數(shù)字世界之間架起橋梁,以實現(xiàn)智能邊緣領(lǐng)域的突破性創(chuàng)新。ADI提供結(jié)合模擬、數(shù)字和軟件技術(shù)的解決方案,推動數(shù)字化工廠、汽車和數(shù)字醫(yī)療等領(lǐng)域的持續(xù)發(fā)展,應(yīng)對氣候變化挑戰(zhàn),并建立人與世界萬物的可靠互聯(lián)。ADI公司2022財年收入超過120億美元,全球員工2.4萬余人。攜手全球12.5萬家客戶,ADI助力創(chuàng)新者不斷超越一切可能。更多信息,請訪問www.analog.com/cn。
關(guān)于作者
Ole Dreessen是ADI公司的現(xiàn)場應(yīng)用工程師,于2014年加入ADI公司,此前曾在Avnet Memec和Macnica任職,負(fù)責(zé)支持通信產(chǎn)品和高性能微處理器。Ole在微控制器和安全方面擁有廣泛的專業(yè)知識,擁有豐富的會議主講經(jīng)驗。在業(yè)余時間,他是混沌計算機俱樂部的活躍成員,主要研究逆向工程和嵌入式安全等概念。
本月熱點 HOME
欄目熱點 HOME
- 業(yè)界資訊
 是德科技 FieldFox 手持式分析儀配合 VDI 擴頻模塊,實現(xiàn)毫米波分析功能
是德科技 FieldFox 手持式分析儀配合 VDI 擴頻模塊,實現(xiàn)毫米波分析功能 -
業(yè)界資訊

推進ECU板對板連接,提升自動駕駛水平
02-06 -
新品報到

阜博集團發(fā)布DreamMaker新產(chǎn)品
03-28 -
業(yè)界資訊

香港生產(chǎn)力促進局2021年「成就智上」年度主題
02-28 -
業(yè)界資訊

西門子收購 Dotmatics,將 AI 驅(qū)動的工業(yè)軟件版圖擴展至生命科學(xué)領(lǐng)域
04-06 -
業(yè)界資訊
西門子收購 Dotmatics,將 AI 驅(qū)動的工業(yè)軟件版圖擴展至生命科學(xué)領(lǐng)域
04-06